
Avance reporte latex
Showing
- docs/latex/report.tex 224 additions, 1 deletiondocs/latex/report.tex
- docs/latex/resources/cinder.png 0 additions, 0 deletionsdocs/latex/resources/cinder.png
- docs/latex/resources/glance.png 0 additions, 0 deletionsdocs/latex/resources/glance.png
- docs/latex/resources/glance2.png 0 additions, 0 deletionsdocs/latex/resources/glance2.png
- docs/latex/resources/keystone.png 0 additions, 0 deletionsdocs/latex/resources/keystone.png
- docs/latex/resources/neutron.png 0 additions, 0 deletionsdocs/latex/resources/neutron.png
- docs/latex/resources/neutron2.png 0 additions, 0 deletionsdocs/latex/resources/neutron2.png
- docs/latex/resources/nova.png 0 additions, 0 deletionsdocs/latex/resources/nova.png
- docs/latex/resources/swift.png 0 additions, 0 deletionsdocs/latex/resources/swift.png
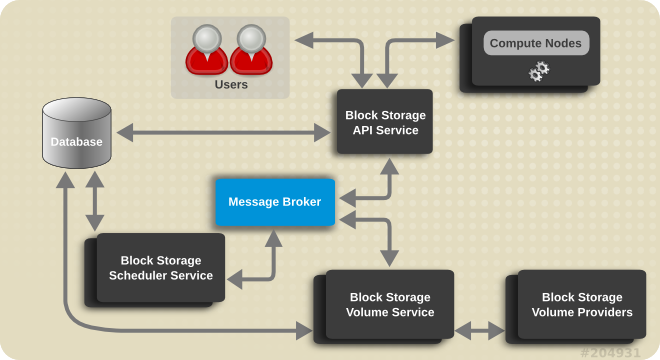
docs/latex/resources/cinder.png
0 → 100644
{kind=link}
101 KiB
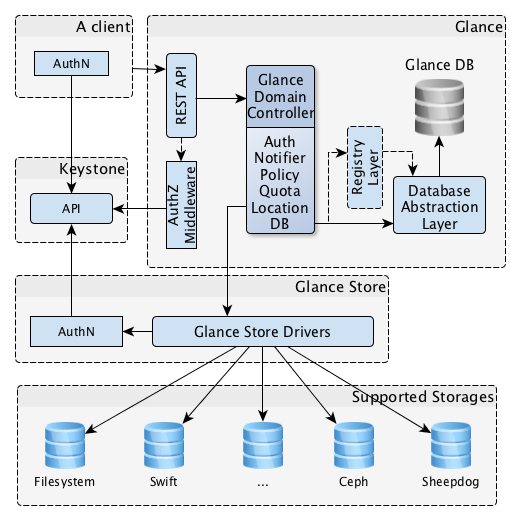
docs/latex/resources/glance.png
0 → 100644
{kind=link}
67.4 KiB
docs/latex/resources/glance2.png
0 → 100644
{kind=link}

35.5 KiB
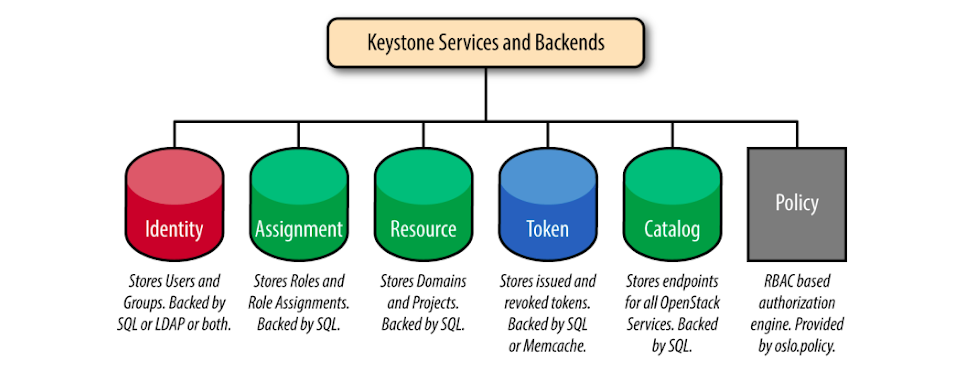
docs/latex/resources/keystone.png
0 → 100644
{kind=link}
111 KiB
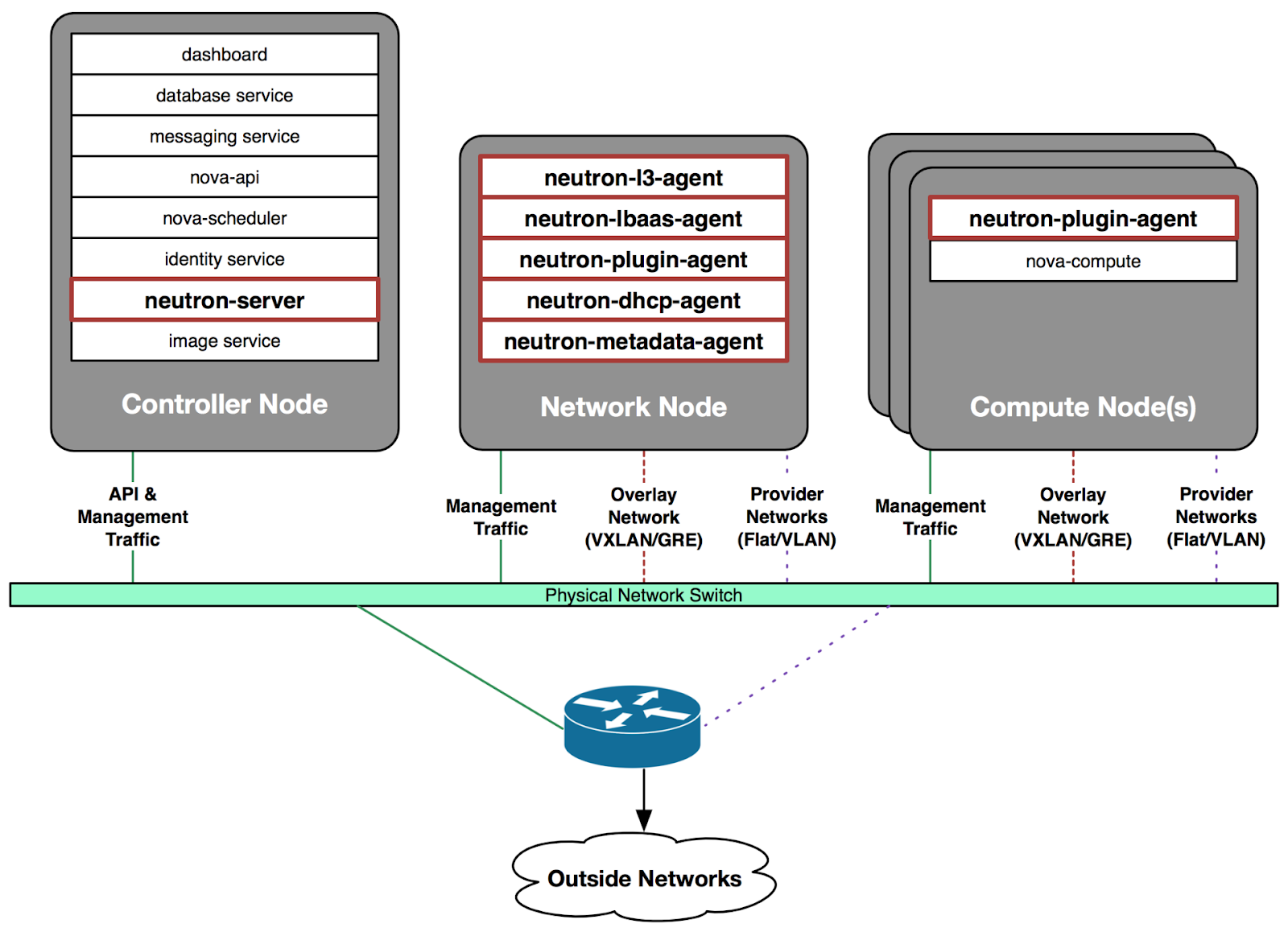
docs/latex/resources/neutron.png
0 → 100644
{kind=link}
285 KiB
docs/latex/resources/neutron2.png
0 → 100644
{kind=link}
163 KiB
docs/latex/resources/nova.png
0 → 100644
{kind=link}
159 KiB
docs/latex/resources/swift.png
0 → 100644
{kind=link}
57.6 KiB